publications
2025
- Preprint
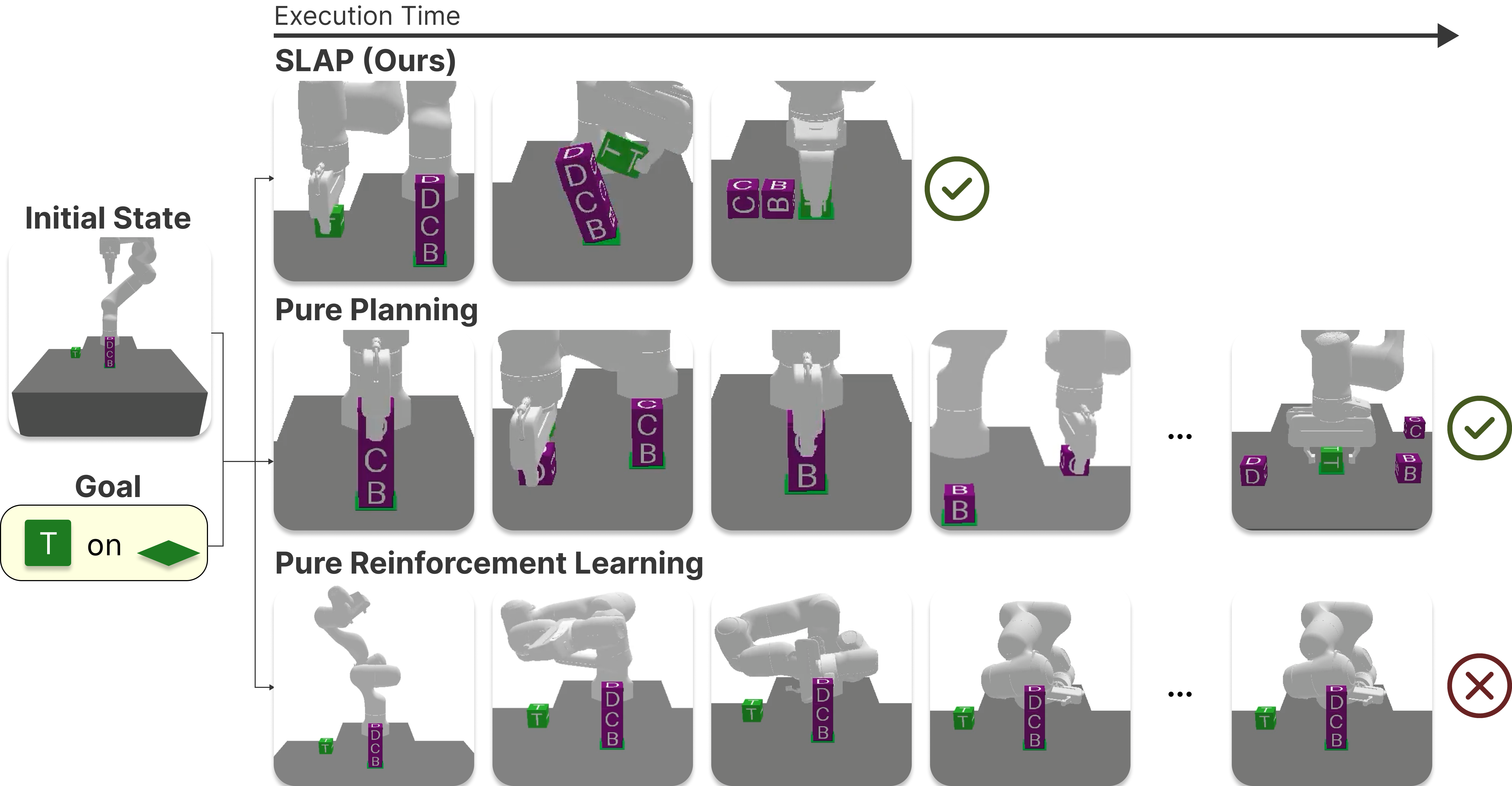 SLAP: Shortcut Learning for Abstract PlanningY. Isabel Liu, Bowen Li, Benjamin Eysenbach, and Tom SilverICLR 2026
SLAP: Shortcut Learning for Abstract PlanningY. Isabel Liu, Bowen Li, Benjamin Eysenbach, and Tom SilverICLR 2026Long-horizon decision-making with sparse rewards and continuous states and actions remains a fundamental challenge in AI and robotics. Task and motion planning (TAMP) is a model-based framework that addresses this challenge by planning hierarchically with abstract actions (options). These options are manually defined, limiting the agent to behaviors that we as human engineers know how to program (pick, place, move). In this work, we propose Shortcut Learning for Abstract Planning (SLAP), a method that leverages existing TAMP options to automatically discover new ones. Our key idea is to use model-free reinforcement learning (RL) to learn shortcuts in the abstract planning graph induced by the existing options in TAMP. Without any additional assumptions or inputs, shortcut learning leads to shorter solutions than pure planning, and higher task success rates than flat and hierarchical RL. Qualitatively, SLAP discovers dynamic physical improvisations (e.g., slap, wiggle, wipe) that differ significantly from the manually-defined ones. In experiments in four simulated robotic environments, we show that SLAP solves and generalizes to a wide range of tasks, reducing overall plan lengths by over 50% and consistently outperforming planning and RL baselines.
@article{liu2025slap, title = {SLAP: Shortcut Learning for Abstract Planning}, author = {Liu, Y. Isabel and Li, Bowen and Eysenbach, Benjamin and Silver, Tom}, journal = {arXiv preprint arXiv:2511.01107}, year = {2025}, }
2024
- IEEE CDC
 Flash stu: Fast spectral transform unitsY. Isabel Liu*, Windsor Nguyen*, Yagiz Devre, Evan Dogariu, Anirudha Majumdar, and Elad HazanIEEE Conference on Decision and Control 2025
Flash stu: Fast spectral transform unitsY. Isabel Liu*, Windsor Nguyen*, Yagiz Devre, Evan Dogariu, Anirudha Majumdar, and Elad HazanIEEE Conference on Decision and Control 2025Recent advances in state-space model architectures have shown great promise for efficient sequence modeling, but challenges remain in balancing computational efficiency with model expressiveness. We propose the Flash STU architecture, a hybrid model that interleaves spectral state space model layers with sliding window attention, enabling scalability to billions of parameters for language modeling while maintaining a near-linear time complexity. We evaluate the Flash STU and its variants on diverse sequence prediction tasks, including linear dynamical systems, robotics control, and language modeling. We find that, given a fixed parameter budget, the Flash STU architecture consistently outperforms the Transformer and other leading state-space models such as S4 and Mamba-2.
@article{liu2024flash, title = {Flash stu: Fast spectral transform units}, author = {Liu, Y. Isabel and Nguyen, Windsor and Devre, Yagiz and Dogariu, Evan and Majumdar, Anirudha and Hazan, Elad}, journal = {arXiv preprint arXiv:2409.10489}, year = {2024}, }